Jeder Entscheidungsbaum hat eine hohe Varianz, aber wenn wir alle Entscheidungsbäume parallel miteinander kombinieren, ist die resultierende Varianz gering, da jeder Entscheidungsbaum perfekt auf die jeweiligen Beispieldaten trainiert wird und somit die Ausgabe nicht von einem Entscheidungsbaum, sondern von mehreren Entscheidungsbäumen abhängt. Im Falle eines Klassifizierungsproblems wird die endgültige Ausgabe durch Verwendung des Klassifizierers mit Mehrheitsabstimmung ermittelt. Im Falle eines Regressionsproblems ist die endgültige Ausgabe der Mittelwert aller Ausgaben. Dieser Teil ist die Aggregation.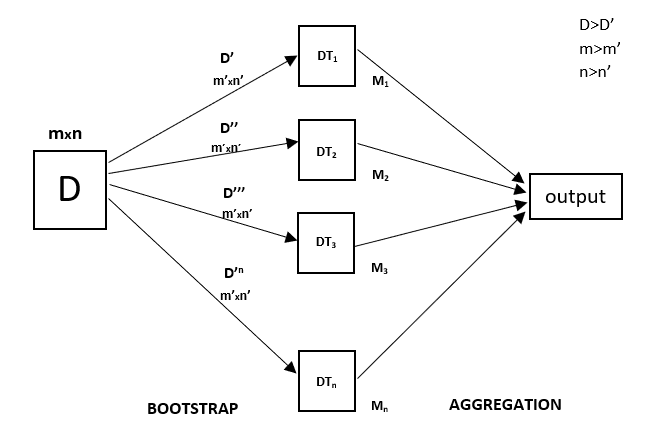
Ein Random Forest ist eine Ensemble-Technik, die in der Lage ist, sowohl Regressions- als auch Klassifikationsaufgaben unter Verwendung mehrerer Entscheidungsbäume und einer Technik namens Bootstrap und Aggregation, allgemein bekannt als Bagging, durchzuführen. Die Grundidee dahinter ist, mehrere Entscheidungsbäume bei der Bestimmung der endgültigen Ausgabe zu kombinieren, anstatt sich auf einzelne Entscheidungsbäume zu verlassen.
Random Forest hat mehrere Entscheidungsbäume als Basis-Lernmodelle. Wir führen ein zufälliges Zeilensampling und Merkmalsampling aus dem Datensatz durch und bilden so Beispieldatensätze für jedes Modell. Dieser Teil wird Bootstrap genannt.
Wir müssen die Random-Forest-Regressionstechnik wie jede andere maschinelle Lerntechnik angehen
- Gestalten Sie eine spezifische Frage oder Daten und besorgen Sie sich die Quelle, um die erforderlichen Daten zu bestimmen.
- Stellen Sie sicher, dass die Daten in einem zugänglichen Format vorliegen, oder konvertieren Sie sie in das erforderliche Format.
- Bestimmen Sie alle auffälligen Anomalien und fehlenden Datenpunkte, die möglicherweise erforderlich sind, um die erforderlichen Daten zu erhalten.
- Erstellen Sie ein maschinelles Lernmodell
- Setzen Sie das Basismodell, das Sie erreichen möchten
- Trainieren Sie das maschinelle Lernmodell für die Daten.
- Geben Sie einen Einblick in das Modell mit
test data - Nun vergleichen Sie die Leistungsmetriken sowohl des
test dataals auch despredicted dataaus dem Modell. - Wenn es Ihre Erwartungen nicht erfüllt, können Sie versuchen, Ihr Modell entsprechend zu verbessern oder Ihre Daten zu datieren oder eine andere Datenmodellierungstechnik zu verwenden.
- In dieser Phase interpretieren Sie die gewonnenen Daten und erstellen einen entsprechenden Bericht.
Im folgenden Beispiel wird eine ähnliche Technik verwendet.
Beispiel
Nachfolgend finden Sie eine Schritt-für-Schritt-Beispielimplementierung der Rando-Forest-Regression.
Schritt 1: Importieren Sie die erforderlichen Bibliotheken.
importnumpy as np importmatplotlib.pyplot as plt importpandas as pd
Schritt 2 : Datensatz importieren und drucken
data =pd.read_csv('Salaries.csv') print(data) 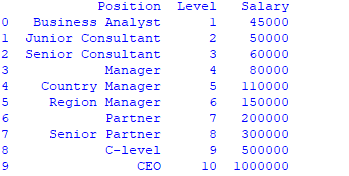
Schritt 3 : Alle Zeilen und Spalte 1 aus dem Datensatz als x und alle Zeilen und Spalte 2 als y auswählen
x = data.iloc.values print(x) y = data.iloc.values 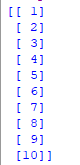

Schritt 4 : Random-Forest-Regressor an den Datensatz anpassen
fromsklearn.ensemble importRandomForestRegressor
regressor =RandomForestRegressor(n_estimators =100, random_state =0) regressor.fit(x, y) 
Schritt 5 : Vorhersage eines neuen Ergebnisses
Y_pred =regressor.predict(np.array().reshape(1, 1)) Schritt 6 : Das Ergebnis visualisieren
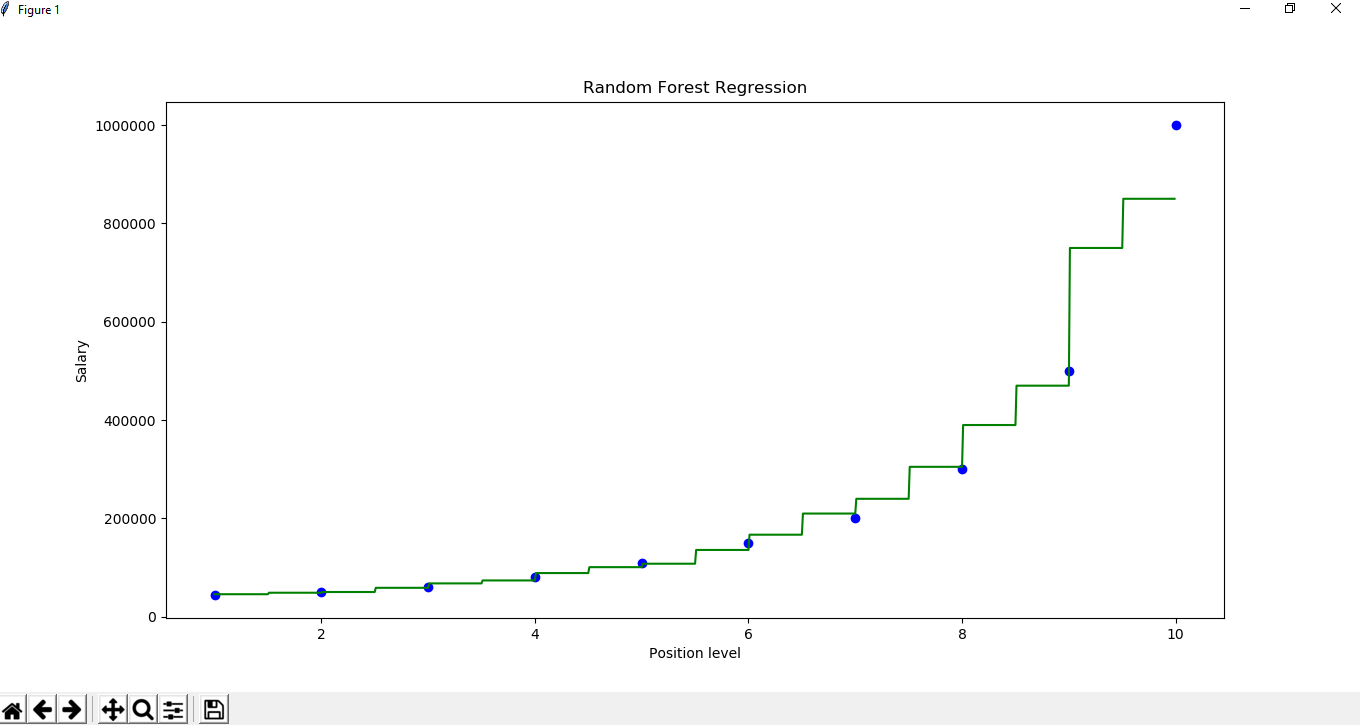
X_grid =np.arange(min(x), max(x), 0.01) X_grid =X_grid.reshape((len(X_grid), 1)) plt.scatter(x, y, color ='blue')
plt.plot(X_grid, regressor.predict(X_grid), color ='green') plt.title('Random Forest Regression') plt.xlabel('Position level') plt.ylabel('Salary') plt.show()