Cada árbol de decisión tiene una alta varianza, pero cuando combinamos todos ellos en paralelo entonces la varianza resultante es baja ya que cada árbol de decisión se entrena perfectamente en esa muestra de datos en particular y por lo tanto la salida no depende de un árbol de decisión sino de múltiples árboles de decisión. En el caso de un problema de clasificación, el resultado final se obtiene utilizando el clasificador por mayoría. En el caso de un problema de regresión, el resultado final es la media de todos los resultados. Esta parte es la Agregación.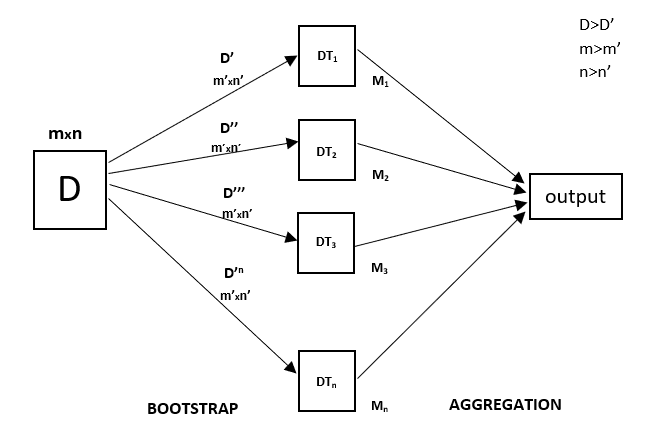
Un Bosque Aleatorio es una técnica de conjunto capaz de realizar tanto tareas de regresión como de clasificación con el uso de múltiples árboles de decisión y una técnica llamada Bootstrap y Agregación, comúnmente conocida como bagging. La idea básica detrás de esto es combinar múltiples árboles de decisión para determinar el resultado final en lugar de confiar en los árboles de decisión individuales.
El Bosque Aleatorio tiene múltiples árboles de decisión como modelos de aprendizaje base. Realizamos aleatoriamente un muestreo de filas y un muestreo de características del conjunto de datos formando conjuntos de datos de muestra para cada modelo. Esta parte se denomina Bootstrap.
Necesitamos abordar la técnica de regresión Random Forest como cualquier otra técnica de aprendizaje automático
- Diseñar una pregunta o datos específicos y obtener la fuente para determinar los datos necesarios.
- Asegurarse de que los datos están en un formato accesible o bien convertirlos al formato requerido.
- Especificar todas las anomalías notables y los puntos de datos que faltan que pueden ser necesarios para lograr los datos requeridos.
- Crear un modelo de aprendizaje automático
- Establecer el modelo de línea de base que se quiere lograr
- Entrenar el modelo de aprendizaje automático de datos.
- Provea una visión del modelo con
test data - Ahora compare las métricas de rendimiento tanto del
test datacomo delpredicted datadel modelo. - Si no satisface sus expectativas, puede intentar mejorar su modelo en consecuencia o fechar sus datos o utilizar otra técnica de modelado de datos.
- En esta etapa usted interpreta los datos que ha obtenido e informa en consecuencia.
Estará utilizando una técnica de muestra similar en el siguiente ejemplo.
Ejemplo
A continuación se muestra un ejemplo de implementación paso a paso de la Regresión Rando Forest.
Paso 1 : Importar las bibliotecas necesarias.
importnumpy as np
importmatplotlib.pyplot as plt importpandas as pd Paso 2 : Importar e imprimir el conjunto de datos
data =pd.read_csv('Salaries.csv')
print(data) 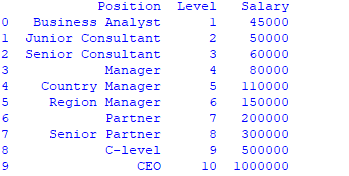
Paso 3 : Seleccionar todas las filas y la columna 1 del conjunto de datos como x y todas las filas y la columna 2 como y
x = data.iloc.values print(x) y = data.iloc.values 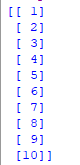

Paso 4 : Ajustar el regresor del bosque aleatorio al conjunto de datos
fromsklearn.ensemble importRandomForestRegressor
regressor =RandomForestRegressor(n_estimators =100, random_state =0)
regressor.fit(x, y) 
Paso 5 : Predicción de un nuevo resultado
Y_pred =regressor.predict(np.array().reshape(1, 1)) Paso 6 : Visualizar el resultado
X_grid =np.arange(min(x), max(x), 0.01)
X_grid =X_grid.reshape((len(X_grid), 1))
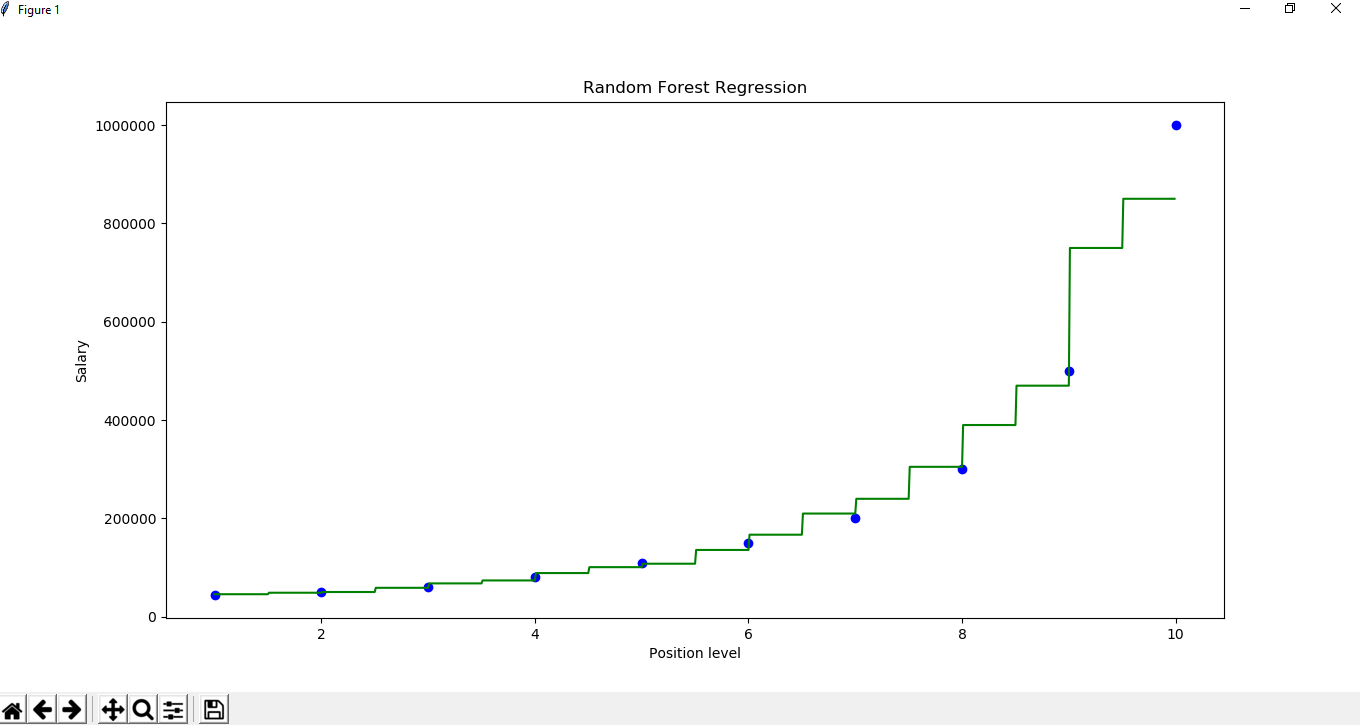
plt.scatter(x, y, color ='blue')
plt.plot(X_grid, regressor.predict(X_grid), color ='green') plt.title('Random Forest Regression')
plt.xlabel('Position level')
plt.ylabel('Salary') plt.show()