Elke beslisboom heeft een hoge variantie, maar als we ze allemaal parallel combineren dan is de resulterende variantie laag omdat elke beslisboom perfect getraind wordt op die specifieke steekproef data en dus hangt de output niet af van één beslisboom maar van meerdere beslisbomen. In het geval van een classificatieprobleem wordt de uiteindelijke output verkregen door gebruik te maken van de meerderheidsstemmende classificator. In het geval van een regressie probleem, is de uiteindelijke output het gemiddelde van alle outputs. Dit deel is Aggregatie.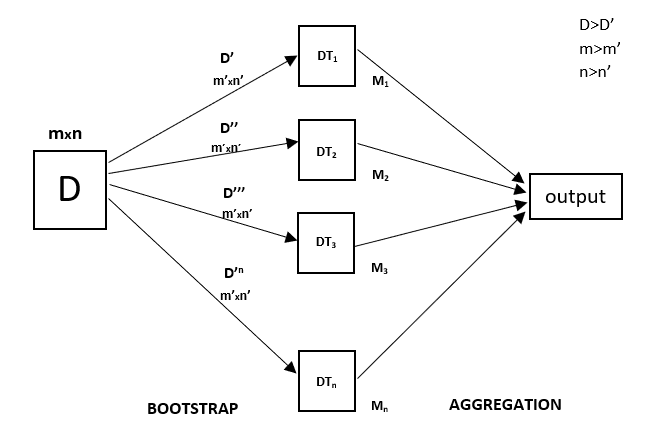
Een Random Forest is een ensembletechniek die in staat is om zowel regressie- als classificatietaken uit te voeren met behulp van meerdere beslisbomen en een techniek die Bootstrap en Aggregatie wordt genoemd, algemeen bekend als bagging. Het basisidee hierachter is om meerdere beslisbomen te combineren bij het bepalen van de uiteindelijke output in plaats van te vertrouwen op individuele beslisbomen.
Random Forest heeft meerdere beslisbomen als basis leermodellen. We voeren willekeurig rijen- en kenmerkenbemonsteringen uit de dataset uit en vormen zo voorbeelddatasets voor elk model. Dit deel heet Bootstrap.
We moeten de Random Forest regressietechniek benaderen als elke andere machine learning techniek
- Ontwerp een specifieke vraag of data en verkrijg de bron om de benodigde data te bepalen.
- Zorg ervoor dat de data in een toegankelijk formaat is anders converteer je het naar het vereiste formaat.
- Bepaal alle opmerkelijke afwijkingen en ontbrekende gegevenspunten die nodig kunnen zijn om de vereiste gegevens te bereiken.
- Maak een machine-learningmodel
- Stel het basismodel vast dat u wilt bereiken
- Train het machine-learningmodel van de gegevens.
- Maak het model inzichtelijk met
test data - Vergelijk nu de performance metrics van zowel de
test dataals depredicted datavan het model. - Als het niet aan je verwachtingen voldoet, kun je proberen je model dienovereenkomstig te verbeteren of je gegevens te dateren of een andere datamodelleringstechniek te gebruiken.
- In dit stadium interpreteer je de data die je hebt verkregen en rapporteer je dienovereenkomstig.
Je zult een vergelijkbare voorbeeld techniek gebruiken in het onderstaande voorbeeld.
Example
Hieronder staat een stap voor stap voorbeeld implementatie van Rando Forest Regression.
Step 1 : Importeer de benodigde bibliotheken.
importnumpy as np importmatplotlib.pyplot as plt importpandas as pd Step 2 : Importeer en print de dataset
data =pd.read_csv('Salaries.csv') print(data) 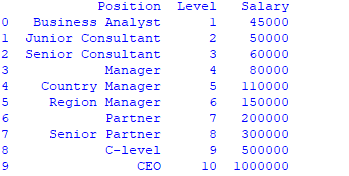
Step 3 : Selecteer alle rijen en kolom 1 uit de dataset als x en alle rijen en kolom 2 als y
x = data.iloc.values print(x) y = data.iloc.values 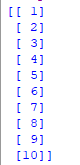

Step 4 : Pas Random forest regressor toe op de dataset
fromsklearn.ensemble importRandomForestRegressor
regressor =RandomForestRegressor(n_estimators =100, random_state =0) regressor.fit(x, y) 
Step 5 : Een nieuw resultaat voorspellen
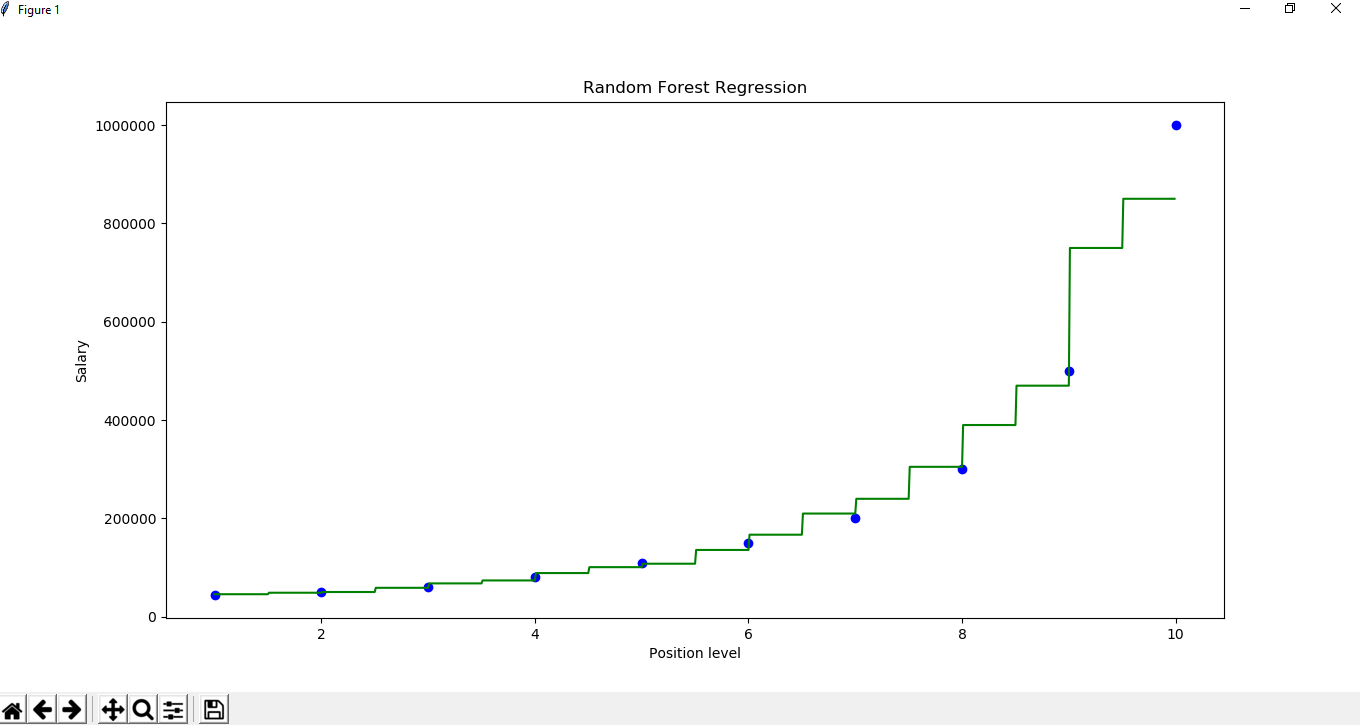
Y_pred =regressor.predict(np.array().reshape(1, 1)) Step 6 : Visualiseren van het resultaat
X_grid =np.arange(min(x), max(x), 0.01) X_grid =X_grid.reshape((len(X_grid), 1)) plt.scatter(x, y, color ='blue') plt.plot(X_grid, regressor.predict(X_grid), color ='green') plt.title('Random Forest Regression') plt.xlabel('Position level') plt.ylabel('Salary') plt.show()