Todas as árvores de decisão têm alta variância, mas quando as combinamos todas em paralelo, então a variância resultante é baixa, uma vez que cada árvore de decisão fica perfeitamente treinada com esses dados de amostra particulares e, portanto, o output não depende de uma árvore de decisão, mas de múltiplas árvores de decisão. No caso de um problema de classificação, o resultado final é obtido utilizando o classificador de votação maioritária. No caso de um problema de regressão, o resultado final é a média de todos os resultados. Esta parte é Aggregation.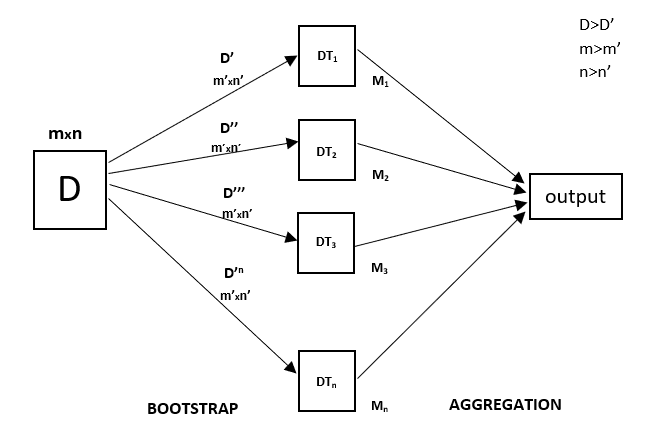
A Random Forest é uma técnica de conjunto capaz de realizar tarefas de regressão e classificação com o uso de árvores de decisão múltipla e uma técnica chamada Bootstrap and Aggregation, vulgarmente conhecida como ensacamento. A ideia básica por detrás disto é combinar árvores de decisão múltipla na determinação do resultado final, em vez de confiar em árvores de decisão individuais.
A Random Forest tem árvores de decisão múltipla como modelos de aprendizagem base. Realizamos aleatoriamente a amostragem em fila e amostramos a partir do conjunto de dados, formando conjuntos de dados de amostra para cada modelo. Esta parte chama-se Bootstrap.
Precisamos de abordar a técnica de regressão de Floresta Aleatória como qualquer outra técnica de aprendizagem de máquinas
- Desenhar uma questão ou dados específicos e obter a fonte para determinar os dados necessários.
- Definir todas as anomalias notáveis e pontos de dados em falta que possam ser necessários para atingir os dados necessários.
- Criar um modelo de aprendizagem da máquina
- Definir o modelo de base que se pretende atingir
- Treinar o modelo de aprendizagem da máquina de dados.
- Prover uma visão do modelo com
test data - Agora compare as métricas de desempenho tanto do
test datacomo dopredicted datado modelo. - se não satisfizer as suas expectativas, pode tentar melhorar o seu modelo em conformidade ou datar os seus dados ou utilizar outra técnica de modelagem de dados.
- Nesta fase interpreta os dados que obteve e informa em conformidade.
li>Certifique-se de que os dados estão num formato acessível, senão converte-os para o formato requerido.
Vai utilizar uma técnica de amostra semelhante no exemplo abaixo.
Exemplo
Below é uma implementação passo a passo da Rando Forest Regression.
P>Passo 1 : Importar as bibliotecas necessárias.
>br>
/p>
>br>>>/p>
importnumpy as np importmatplotlib.pyplot as plt importpandas as pd br>>>/div>
/p>
>br>>/p>
data =pd.read_csv('Salaries.csv') print(data) 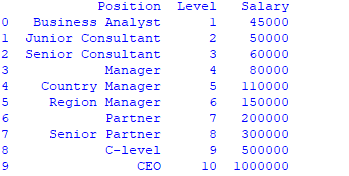
br>passo 3 : Seleccione todas as linhas e coluna 1 do conjunto de dados para x e todas as linhas e coluna 2 como y
>/p>p>
x = data.iloc.values print(x) y = data.iloc.values 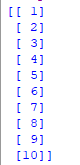 br>>
br>> br>>passo 4 : Adaptar o regressor florestal aleatório ao conjunto de dados
br>>passo 4 : Adaptar o regressor florestal aleatório ao conjunto de dados
>/p>
>/p>
fromsklearn.ensemble importRandomForestRegressor regressor =RandomForestRegressor(n_estimators =100, random_state =0) regressor.fit(x, y) br>>>/div>
 br>passo 5 : Previsão de um novo resultado
br>passo 5 : Previsão de um novo resultado
/p>
>/p>
Y_pred =regressor.predict(np.array().reshape(1, 1)) /p>
>br>>/p>
/div>
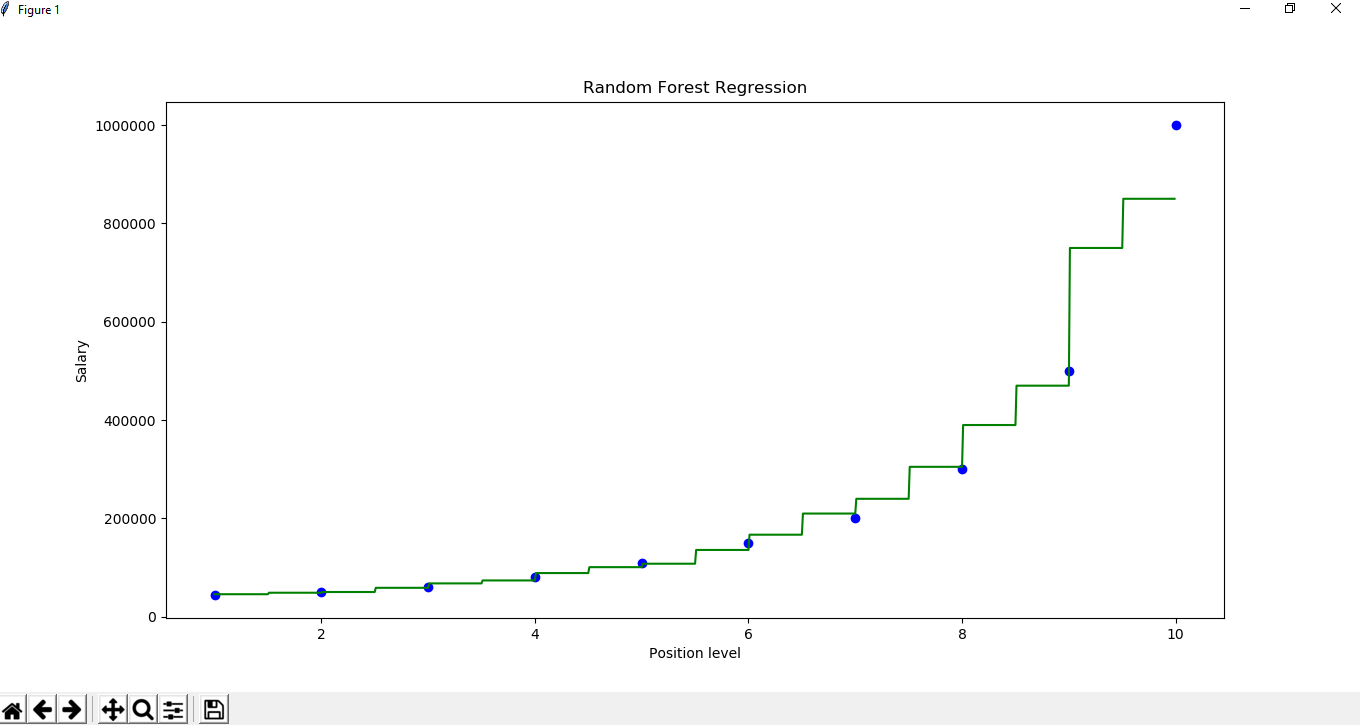
X_grid =np.arange(min(x), max(x), 0.01) X_grid =X_grid.reshape((len(X_grid), 1)) plt.scatter(x, y, color ='blue') plt.plot(X_grid, regressor.predict(X_grid), color ='green') plt.title('Random Forest Regression') plt.xlabel('Position level') plt.ylabel('Salary') plt.show()>br>>>/div>