Ogni albero decisionale ha un’alta varianza, ma quando li combiniamo tutti insieme in parallelo allora la varianza risultante è bassa perché ogni albero decisionale viene perfettamente addestrato su quel particolare campione di dati e quindi l’output non dipende da un albero decisionale ma da più alberi decisionali. Nel caso di un problema di classificazione, l’output finale viene preso utilizzando il classificatore con voto di maggioranza. Nel caso di un problema di regressione, l’output finale è la media di tutti gli output. Questa parte è l’aggregazione.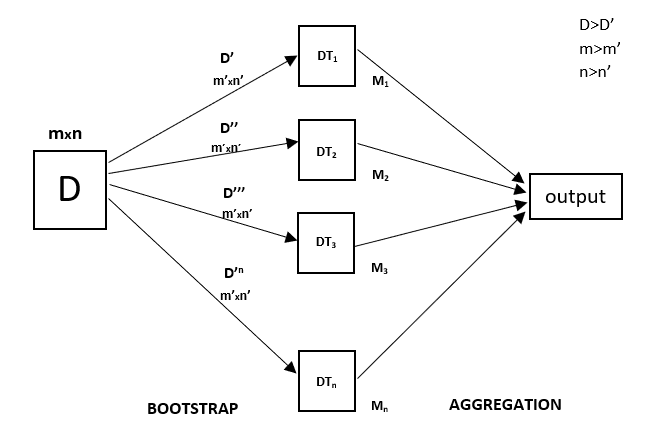
Una foresta casuale è una tecnica di ensemble in grado di eseguire sia compiti di regressione che di classificazione con l’uso di più alberi decisionali e una tecnica chiamata Bootstrap e aggregazione, comunemente nota come bagging. L’idea di base è quella di combinare più alberi decisionali nel determinare l’output finale piuttosto che fare affidamento su alberi decisionali individuali.
Random Forest ha più alberi decisionali come modelli di apprendimento di base. Eseguiamo casualmente il campionamento delle righe e delle caratteristiche dal set di dati formando set di dati campione per ogni modello. Questa parte è chiamata Bootstrap.
Dobbiamo approcciare la tecnica di regressione Random Forest come qualsiasi altra tecnica di apprendimento automatico
- Progettare una domanda o dati specifici e ottenere la fonte per determinare i dati richiesti.
- Assicurarsi che i dati siano in un formato accessibile o convertirli nel formato richiesto.
- Specificare tutte le anomalie evidenti e i punti di dati mancanti che possono essere necessari per ottenere i dati richiesti.
- Creare un modello di apprendimento automatico
- Impostare il modello di base che si vuole ottenere
- Allena il modello di apprendimento automatico dei dati.
- Fate una panoramica del modello con
test data - Ora confrontate le metriche di performance sia del
test datache delpredicted datadel modello. - Se non soddisfa le vostre aspettative, potete provare a migliorare il vostro modello di conseguenza o datare i vostri dati o usare un’altra tecnica di modellazione dei dati.
- In questa fase interpreti i dati che hai ottenuto e li riporti di conseguenza.
Utilizzerai una tecnica di esempio simile nell’esempio seguente.
Esempio
Di seguito è riportato un esempio di implementazione passo dopo passo della Rando Forest Regression.
Step 1 : Importa le librerie necessarie.
importnumpy as np importmatplotlib.pyplot as plt importpandas as pd Step 2 : Importare e stampare il set di dati
data =pd.read_csv('Salaries.csv') print(data) 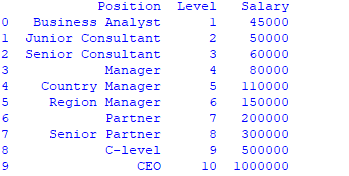
Step 3 : Selezionare tutte le righe e la colonna 1 dal dataset in x e tutte le righe e la colonna 2 come y
x = data.iloc.values print(x) y = data.iloc.values 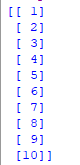

Step 4 : Adattare il regressore Random forest al set di dati
fromsklearn.ensemble importRandomForestRegressor regressor =RandomForestRegressor(n_estimators =100, random_state =0) regressor.fit(x, y) 
Step 5 : Prevedere un nuovo risultato
Y_pred =regressor.predict(np.array().reshape(1, 1)) Step 6 : Visualizzare il risultato
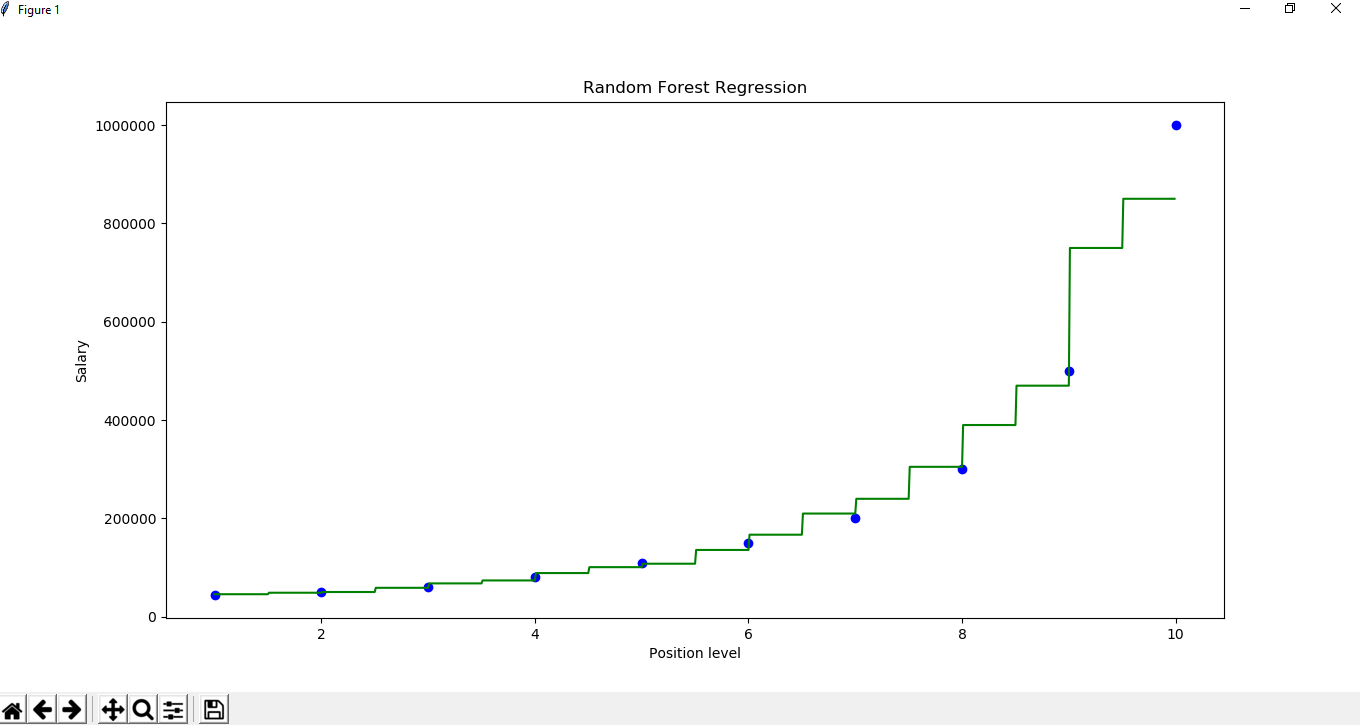
X_grid =np.arange(min(x), max(x), 0.01) X_grid =X_grid.reshape((len(X_grid), 1)) plt.scatter(x, y, color ='blue') plt.plot(X_grid, regressor.predict(X_grid), color ='green') plt.title('Random Forest Regression') plt.xlabel('Position level') plt.ylabel('Salary') plt.show()