Chaque arbre de décision a une variance élevée, mais lorsque nous les combinons tous ensemble en parallèle, alors la variance résultante est faible car chaque arbre de décision est parfaitement formé sur cet échantillon de données particulier et donc la sortie ne dépend pas d’un arbre de décision mais de plusieurs arbres de décision. Dans le cas d’un problème de classification, le résultat final est obtenu en utilisant le classificateur à vote majoritaire. Dans le cas d’un problème de régression, la sortie finale est la moyenne de toutes les sorties. Cette partie est l’agrégation.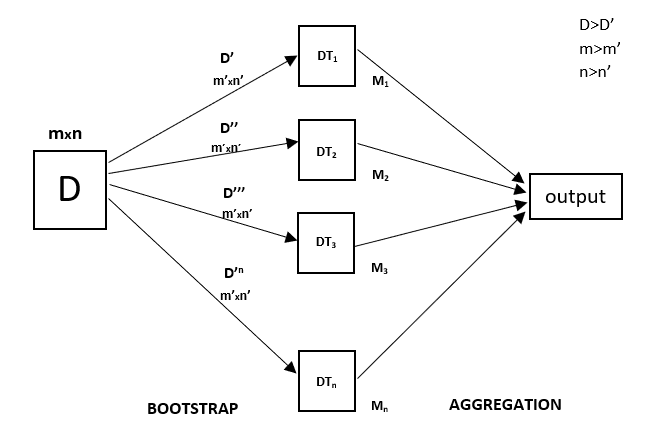
Une Random Forest est une technique d’ensemble capable d’effectuer à la fois des tâches de régression et de classification avec l’utilisation de plusieurs arbres de décision et d’une technique appelée Bootstrap et agrégation, communément appelée bagging. L’idée de base derrière cela est de combiner plusieurs arbres de décision pour déterminer la sortie finale plutôt que de s’appuyer sur des arbres de décision individuels.
La forêt aléatoire a plusieurs arbres de décision comme modèles d’apprentissage de base. Nous effectuons de manière aléatoire l’échantillonnage des lignes et l’échantillonnage des caractéristiques à partir de l’ensemble de données formant des ensembles de données d’échantillon pour chaque modèle. Cette partie est appelée Bootstrap.
Nous devons aborder la technique de régression Random Forest comme toute autre technique d’apprentissage automatique
- Concevoir une question ou des données spécifiques et obtenir la source pour déterminer les données requises.
- S’assurer que les données sont dans un format accessible sinon les convertir au format requis.
- Spécifier toutes les anomalies notables et les points de données manquants qui peuvent être nécessaires pour obtenir les données requises.
- Créer un modèle d’apprentissage automatique
- Définir le modèle de base que vous voulez atteindre
- Entraîner le modèle d’apprentissage automatique des données.
- Donnez un aperçu du modèle avec
test data - Maintenant, comparez les métriques de performance à la fois du
test dataet dupredicted datadu modèle. - Si cela ne répond pas à vos attentes, vous pouvez essayer d’améliorer votre modèle en conséquence ou de dater vos données ou d’utiliser une autre technique de modélisation des données.
- À ce stade, vous interprétez les données que vous avez obtenues et faites un rapport en conséquence.
Vous utiliserez un exemple de technique similaire dans l’exemple ci-dessous.
Exemple
Vous trouverez ci-dessous un exemple de mise en œuvre étape par étape de la régression Rando Forest.
Étape 1 : Importer les bibliothèques requises.
importnumpy as np
importmatplotlib.pyplot as plt importpandas as pd Étape 2 : Importer et imprimer le jeu de données
data =pd.read_csv('Salaries.csv') print(data) 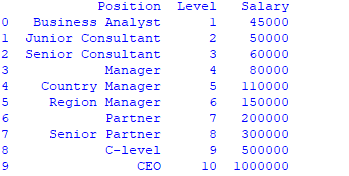
Étape 3 : Sélectionner toutes les lignes et la colonne 1 du jeu de données en x et toutes les lignes et la colonne 2 en y
.
x = data.iloc.values print(x) .
y = data.iloc.values .
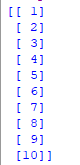

Étape 4 : Ajuster le régresseur Random forest au jeu de données
.
fromsklearn.ensemble
import RandomForestRegressor
regressor =RandomForestRegressor(n_estimators =100, random_state
=0) regressor.fit(x, y) .

Étape 5 : Prédire un nouveau résultat
.
Y_pred =regressor.predict(np.array().reshape(
1, 1))
Étape 6 : Visualisation du résultat
.
X_grid
= np.arange(min(x), max(x), 0.01)
X_grid =X_grid.reshape((len(X_grid), 1)) . plt.scatter(x, y, color ='blue') plt.plot(X_grid, regressor.predict(X_grid), .
color ='green') plt.title('Random Forest Regression')
plt.xlabel('Position level') plt.ylabel('Salary') plt.show()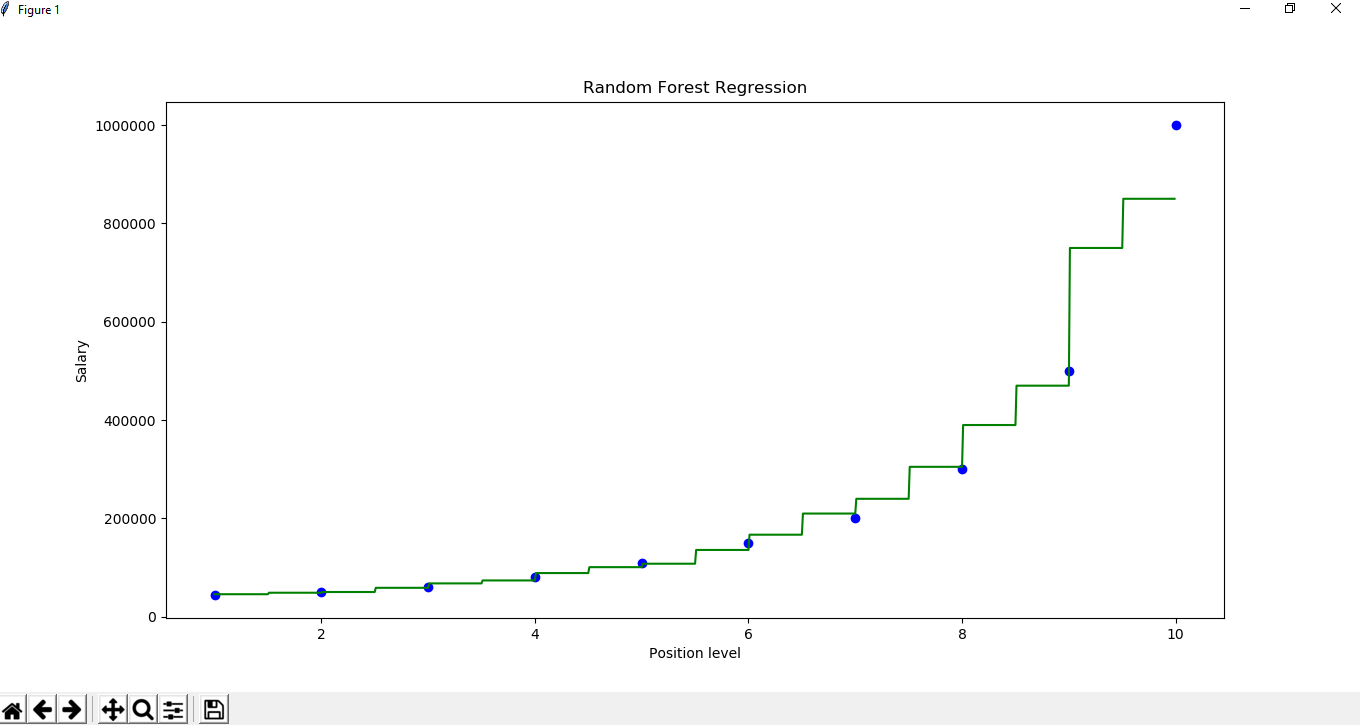
 .
.